Inhaltsverzeichnis
Warum Fragebögen mit R auswerten?
Immer mehr Hochschulen verlangen heute eine empirische Arbeit. Grund dafür ist das Aufkommen von KI-Werkzeugen wie ChatGPT. Eine reine Literaturarbeit gilt vielen Prüfern inzwischen als „zu einfach". Der empirische Teil wird oft mit einem Fragebogen verbunden. Doch wie kann man einen Fragebogen auswerten? Welche Software eignet sich für die Auswertung eines Fragebogens? In diesem Beitrag widmen wir uns dem Thema Fragebogen auswerten mit R.
Ob es um die statistische Auswertung von Fragebögen für Bachelorarbeiten geht, die Auswertung einer Befragung im Rahmen eines Forschungsprojekts oder das Likert Skala auswerten in einer Mitarbeiterbefragung — bei jeder Auswertung Befragung gilt: passende Methodik wählen — der Prozess folgt immer ähnlichen Schritten. Auch bei geschlossenen Fragen mit Skalen wie „stimme voll zu" bis „stimme eher nicht zu" lassen sich mit den richtigen statistischen Tests aussagekräftige Ergebnisse gewinnen. Wichtig ist dabei, sich vorab einen Überblick über die Daten zu verschaffen, um die passenden Skalen für Fragebogen-Items korrekt zu interpretieren.
Die Nutzung der Software R für die Auswertung von Fragebögen ist grundsätzlich kostenlos. Dennoch ist das Verwenden nicht ganz so einfach. Falls Sie Hilfe benötigen, übernehmen wir gerne die professionelle Fragebogenauswertung für Sie.
Möchten Sie Ihren Fragebogen auswerten lassen? Wir übernehmen die komplette Analyse in R, SPSS oder Excel — diskret, präzise und termingerecht.
Fragebogen auswerten lassenCharakteristika von Fragebögen
Eine Umfrage ist eine Forschungsmethode. Sie dient dazu, Informationen von einer Stichprobe zu sammeln. Fragebögen sind dabei das zentrale Forschungsinstrument. Sie bilden typischerweise einen Teil einer Umfrage. In diesem Teil beantworten Teilnehmende eine Reihe von Fragen.
Fragebögen werden meist als schriftliche Instrumente definiert. Sie präsentieren Befragten Fragen oder Aussagen. Diese werden entweder schriftlich beantwortet oder aus vorgegebenen Antworten ausgewählt.
Der Fragebogen erfasst drei Arten von Daten:
- Faktische Daten: „Wie alt sind Sie?" oder „In welchem Bundesland wohnen Sie?"
- Verhaltensbezogene Daten: „Wie oft nutzen Sie öffentliche Verkehrsmittel pro Woche?"
- Einstellungsmäßige Daten: „Wie zufrieden sind Sie mit Ihrem Arbeitsplatz?" (Skala von 1 bis 10)
Faktische und verhaltensbezogene Fragen zielen darauf ab, was eine Person ist oder tut. Einstellungsmäßige Fragen konzentrieren sich darauf, was die Person denkt oder fühlt.
Vorteile von Umfragen
Umfragen bieten viele Vorteile. Sie sind eine günstige, schnelle und effektive Möglichkeit der Datenerhebung. Auch gezielte Daten von einer großen Anzahl an Personen lassen sich so erfassen. Zudem können Umfragen auf unterschiedliche Weise durchgeführt werden — persönlich, telefonisch, computergestützt, über soziale Medien oder postalisch.
Nachteile von Umfragen
Ein Nachteil von Fragebögen ist die Anfälligkeit für unzuverlässige Daten. Die Ergebnisse können durch soziale Erwünschtheit beeinflusst werden. Teilnehmende neigen dazu, Antworten zu geben, die von anderen positiv wahrgenommen werden. Dadurch sind die Ergebnisse möglicherweise nicht repräsentativ für das tatsächliche Verhalten.
Trotz dieser Nachteile gehören Fragebögen zu den gängigsten Forschungsdesigns in der empirischen Forschung.
Tipps für die Erstellung eines Fragebogens
Wer einen Fragebogen erstellen möchte, sollte einige grundlegende Dinge beachten. Nur so liefert die Umfrage aussagekräftige Ergebnisse.
1. Länge und Fokus
Ein guter Fragebogen ist kurz und prägnant. Niemand möchte einen endlos langen Fragebogen ausfüllen. Trotzdem muss er alle relevanten Daten abdecken. Dazu zählen grundlegende Informationen wie Alter oder Geschlecht. Hier gilt: lieber fokussiert bleiben und nur notwendige Fragen stellen.
2. Klare Sprache
Die Fragen sollten leicht verständlich sein. Also kein Fachchinesisch. Vermeiden Sie außerdem suggestive Formulierungen. Fragen wie „Finden Sie nicht auch, dass…?" führen schnell zu verfälschten Antworten.
3. Testen ist Pflicht
Bevor ein Fragebogen verteilt wird, sollte er getestet werden. Lassen Sie ihn von einigen Personen ausfüllen. Diese sollten ehrlich Feedback geben. So finden Sie heraus, ob die Fragen verständlich sind und wie lange die Beantwortung dauert. Spätere Überraschungen werden so vermieden.
4. Reihenfolge und Struktur
Die Reihenfolge der Fragen spielt eine größere Rolle, als man denkt. Generell gilt: erst allgemeine Fragen, dann spezifischere. Bei verschiedenen Themenblöcken sollten ähnliche Fragen zusammengefasst werden. Die Reihenfolge innerhalb eines Blocks darf variieren. So lassen sich Ermüdungseffekte vermeiden.
5. Präzise Fragen stellen
Eine Frage — ein Thema. Mehrere Aspekte in einer Frage führen schnell zu Missverständnissen. Statt „Sind Sie mit der Qualität und dem Service zufrieden?" besser zwei separate Fragen stellen: „Wie zufrieden sind Sie mit der Qualität?" und „Wie zufrieden sind Sie mit dem Service?"
6. Kontrollfragen einbauen
Kontrollfragen helfen, die Aufmerksamkeit der Befragten zu prüfen. Sie sind so gestaltet, dass sie entgegengesetzte Aussagen testen. Wenn jemand bei zwei widersprüchlichen Fragen dasselbe antwortet, deutet das auf ungenaue Antworten hin.
7. Antwortskalen sinnvoll nutzen
Antwortmöglichkeiten sollten gut durchdacht sein. Es gibt verschiedene Arten von Skalen:
- Nominale Skalen: Einfache Antwortoptionen wie „Ja" oder „Nein".
- Ordinale Skalen: Für Bewertungen oder Meinungen — zum Beispiel mit einer Skala von „stimme gar nicht zu" bis „stimme voll zu".
- Numerische Skalen: Hier sind sowohl Abstände als auch Verhältnisse bedeutsam — etwa bei Alter oder Einkommen.
Ordinale Skalen wie die bekannte Likert-Skala eignen sich besonders gut, um Meinungen zu erfassen. Die typische 5-Stufen-Skala reicht von 1 = stimme nicht zu bis 5 = stimme voll zu. Achten Sie auf die Mittelkategorie: Diese ermöglicht eine neutrale Antwort oder zwingt zur Entscheidung.
Ein gut durchdachter Fragebogen liefert viele wertvolle Informationen. Voraussetzung: Er ist klar, strukturiert und ansprechend gestaltet. Nehmen Sie sich Zeit für die Formulierung und das Testen. Die Ergebnisse werden es Ihnen danken.
Visualisierung von Umfragedaten mit R
Die gesammelten Daten aus Ihrer durchgeführten Umfrage — egal ob als Online-Umfrage, Online Umfrage über Tools wie SoSci Survey oder als Papier-Fragebogen erhoben — lassen sich in RStudio systematisch aufbereiten. Wir empfehlen, zuerst einen Überblick über die Daten zu verschaffen. Welche Fragetypen wurden gestellt? Wie viele geschlossene Fragen mit Antwortskalen wie „stimme voll zu" oder „stimme eher zu" gibt es? Welche offenen Fragen müssen separat kodiert werden? Erst danach kommen die statistischen Tests wie t-Test, ANOVA oder Chi-Quadrat zum Einsatz — abhängig vom Datentyp.
Die Daten aus Umfragen und Fragebögen können in unterschiedlichen Formen vorliegen. Entsprechend gibt es zahlreiche Möglichkeiten der visuellen Darstellung. Hier werfen wir einen Blick auf einige gängige Ansätze. Auch deren Umsetzung in R wird erklärt.
Vorbereitung der Arbeitsumgebung
Bevor mit der Visualisierung begonnen wird, sollten alle benötigten Pakete installiert sein. Für R-Nutzer empfiehlt sich der Einsatz gängiger Bibliotheken: ggplot2, dplyr oder tidyverse. Diese bieten leistungsstarke Tools für Datenverarbeitung und Visualisierung.
Für Likert-Skalen sind zudem spezielle Pakete hilfreich — etwa das Paket likert. Die Installation erfolgt mit install.packages("paketname"). Nach der Installation aktivieren Sie die Pakete mit library(paketname).
Anbei ein Beispielcode für besseres Verständnis:
# Installation und Aktivierung von tidyverse
install.packages("tidyverse") # Installiere das Paket tidyverse
library(tidyverse) # Lade das Paket tidyverse in die R-Umgebung
# Beispiel für die Anwendung von tidyverse-Funktionen
# Erstellen eines DataFrames
daten <- data.frame(
Kategorie = c("A", "B", "C"),
Werte = c(10, 20, 30)
)
# Visualisierung mit ggplot2 (Teil des tidyverse)
daten %>%
ggplot(aes(x = Kategorie, y = Werte, fill = Kategorie)) +
geom_col() +
theme_minimal() +
labs(
title = "Beispieldiagramm mit tidyverse",
x = "Kategorie",
y = "Werte"
)
Sie können den Code direkt in Ihre R-Console eingeben und auf „Run" klicken.
Visualisierung von Likert-Skalen-Daten
Eine häufige Herausforderung bei Umfragedaten ist die Darstellung von Likert-Skalen. Diese erfassen oft Zufriedenheits- oder Meinungsdaten. Die Antworten nehmen typischerweise Werte von 1 (sehr unzufrieden) bis 5 (sehr zufrieden) an.
Eine effektive Möglichkeit der Visualisierung sind kumulative Diagramme. Solche Diagramme zeigen die Häufigkeit der Antworten in aufsteigender Reihenfolge. Unterschiede in Präferenzen oder Meinungen werden so klar sichtbar.
Beispiel: Zufriedenheit mit Kursen
Stellen wir uns folgendes Szenario vor: Wir haben Daten zur Zufriedenheit von Studierenden mit drei Kursen. Diese Daten sind in zwei Spalten organisiert. Eine Spalte enthält den Kursnamen — etwa „Kurs A" oder „Kurs B". Die zweite Spalte enthält die Bewertungen von 1 bis 5.
Mit ggplot2 erstellen wir ein Diagramm. Dieses zeigt die kumulative Häufigkeitsverteilung der Bewertungen für jeden Kurs. Der Fachbegriff lautet: kumulativer Density Plot. Der Code sieht so aus:
library(ggplot2)
# Beispielhafte Datenerstellung
daten <- data.frame(
Kurs = rep(c("Kurs A", "Kurs B", "Kurs C"), each = 100),
Zufriedenheit = sample(1:5, 300, replace = TRUE)
)
# Erstellung des Diagramms
ggplot(daten, aes(x = Zufriedenheit, color = Kurs)) +
stat_ecdf(geom = "step") +
labs(y = "Kumulative Häufigkeit", x = "Bewertungsskala") +
scale_x_continuous(breaks = 1:5, labels = c("sehr unzufrieden",
"unzufrieden", "neutral", "zufrieden", "sehr zufrieden")) +
theme_minimal()
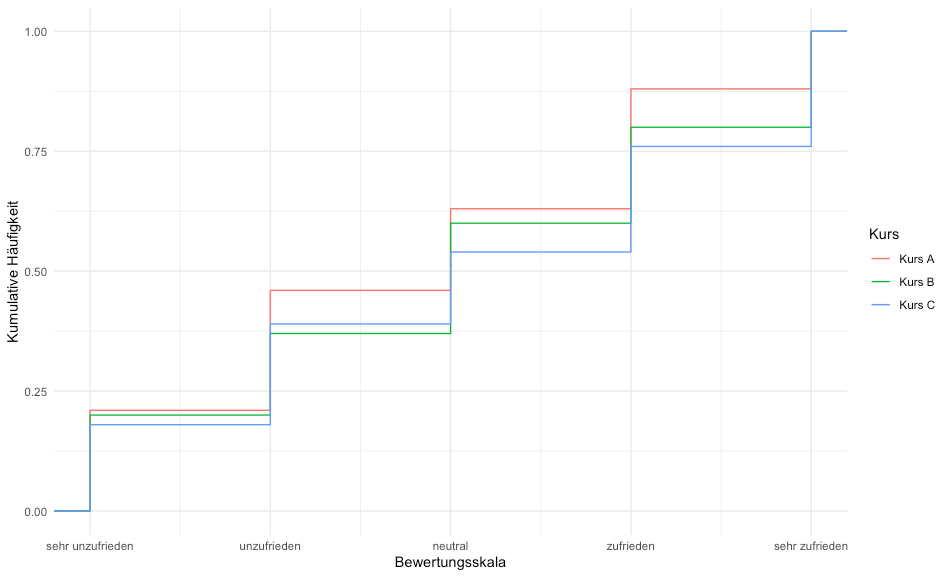
Das Diagramm zeigt die kumulative Häufigkeitsverteilung der Zufriedenheit. Auf der y-Achse sehen Sie, wie viel Prozent der Bewertungen unterhalb einer bestimmten Stufe liegen. Auf der x-Achse ist die Zufriedenheitsskala abgebildet — von „sehr unzufrieden" bis „sehr zufrieden". Die Linien der Kurse steigen stufenweise an. Die kumulative Häufigkeit nimmt mit jeder Stufe zu.
Die Unterschiede zwischen den Kursen A, B und C sind gering. Das erkennen Sie daran, dass die Linien weitgehend übereinstimmen. Kleine Abweichungen sind bei höheren Zufriedenheitswerten sichtbar. Das deutet darauf hin, dass die Zufriedenheit in einem Kurs minimal besser oder schlechter ausfällt. Insgesamt ist die Verteilung der Bewertungen in allen drei Kursen ähnlich.
Hinweis zum Code: Kurs wiederholt die Namen „Kurs A", „Kurs B" und „Kurs C" jeweils 100-mal. Insgesamt gibt es 300 Zeilen. Zufriedenheit erstellt zufällige Bewertungen von 1 bis 5. Die Option replace = TRUE sorgt dafür, dass eine Zahl mehrfach vorkommen kann. Deswegen sieht die Grafik jedes Mal anders aus.
Die Visualisierung in R ermöglicht es, komplexe Informationen verständlich darzustellen. Bei Likert-Skalen bieten kumulative Diagramme einen klaren Überblick. Mit den richtigen Paketen lassen sich aussagekräftige Grafiken erstellen — sowohl für die Datenanalyse als auch für Präsentationen. Datensätze zum Üben finden Sie auf Kaggle.
Fragebogen mit Excel oder SPSS auswerten
Neben R sind Excel und SPSS die häufigsten Programme zur Fragebogenauswertung. Welches Tool das richtige ist, hängt von mehreren Faktoren ab: der Komplexität, den Vorkenntnissen und den Anforderungen Ihrer Hochschule oder Ihres Unternehmens.
Fragebogen mit Excel auswerten
Die Auswertung mit Excel ist die einsteigerfreundlichste Methode. Sie eignet sich besonders für kleinere Studien:
- Pivot-Tabellen: Schnelle Häufigkeitsanalysen ohne Programmierung
- MITTELWERT-Funktion: Berechnung von Durchschnittswerten für Likert-Skalen
- ZÄHLENWENN: Antworten nach Kategorien zählen
- Diagramme: Balken-, Kreis- und Säulendiagramme mit wenigen Klicks
- Datenanalyse-Add-In: t-Tests, Regression und Korrelation
Die Auswertung eines Fragebogens mit Excel stößt allerdings an Grenzen. Bei großen Datenmengen über 100.000 Zeilen oder komplexen multivariaten Verfahren sind R oder SPSS besser geeignet.
Fragebogen mit SPSS auswerten
Die Fragebogenauswertung mit SPSS ist im akademischen Umfeld der Goldstandard:
- Reliabilitätsanalyse: Cronbachs Alpha für die Konsistenz von Skalen
- Faktorenanalyse: Reduzierung vieler Items auf wenige Faktoren
- Mittelwertvergleiche: t-Test und ANOVA per Klick
- Regressionen: Lineare, logistische und multiple Regression
- APA-Export: Tabellen direkt im APA-Format für Abschlussarbeiten
Welches Tool für welchen Fall?
| Anwendungsfall | Empfehlung | Begründung |
|---|---|---|
| Bachelorarbeit, kleine Stichprobe | Excel oder SPSS | Einfache Häufigkeiten und Mittelwerte reichen |
| Masterarbeit, komplexe Hypothesen | SPSS oder R | Regressionen und Faktorenanalysen nötig |
| Doktorarbeit, Publikation | R oder SPSS | Reproduzierbarkeit und Methodenvielfalt |
| Unternehmensstudie | R, SPSS oder Python | Skalierbarkeit und Automatisierung |
| Likert-Skalen visualisieren | R (ggplot2, likert) | Beste Visualisierungsmöglichkeiten |
Fragebogen auswerten lassen — wann sinnvoll?
Manchmal lohnt es sich, die Fragebogenauswertung professionell durchführen zu lassen. Besonders dann, wenn Zeit knapp ist oder die Methodik komplex wird. Typische Situationen für externe Unterstützung:
- Enge Deadline: Wenn die Abgabe der Bachelor- oder Masterarbeit in 2-4 Wochen ansteht
- Komplexe Skalen: Validierte Fragebögen mit mehreren Faktoren erfordern Erfahrung
- Große Stichprobe: Bei mehreren hundert Teilnehmern wird die manuelle Arbeit aufwändig
- Fehlende R- oder SPSS-Kenntnisse: Einarbeitung dauert oft länger als gedacht
- Methodische Beratung: Welcher Test ist der richtige? Welche Skalen sind valide?
Eine professionelle Fragebogenauswertung umfasst typischerweise:
- Datenaufbereitung und Behandlung fehlender Werte
- Reliabilitätsanalyse mit Cronbachs Alpha
- Deskriptive Statistik (Mittelwerte, Häufigkeiten, Standardabweichungen)
- Inferenzstatistik (Hypothesentests, Regressionen)
- Visualisierungen und APA-konforme Tabellen
- Verständliche Ergebnisinterpretation
Statistikerhub übernimmt Ihre Fragebogenauswertung — in R, SPSS oder Excel. Für Bachelorarbeit, Masterarbeit, Doktorarbeit oder Unternehmensstudie.
Unverbindliches Angebot anfragenFAQ — Häufige Fragen zur Fragebogenauswertung
Die statistische Auswertung eines Fragebogens folgt einem klaren Ablauf:
- Daten importieren: Antworten aus CSV, Excel oder Unipark in R, SPSS oder Excel laden
- Variablen kodieren: Antwortoptionen als Zahlenwerte definieren (z. B. 1 = trifft zu, 5 = trifft nicht zu)
- Deskriptive Statistik: Häufigkeiten, Mittelwerte und Standardabweichungen pro Frage berechnen
- Reliabilität prüfen: Cronbachs Alpha für zusammengehörige Skalen berechnen (Wert > 0,7 ist gut)
- Hypothesentests: Je nach Fragestellung t-Tests, ANOVA oder Korrelationen durchführen
- Visualisierung: Ergebnisse mit Diagrammen darstellen
Die Fragebogenauswertung mit Excel eignet sich besonders für kleinere Studien und einfache Analysen:
- Antwortdaten in eine Tabelle laden (eine Spalte pro Frage, eine Zeile pro Teilnehmer)
- Pivot-Tabellen für schnelle Häufigkeitsanalysen erstellen
- Mittelwerte mit
=MITTELWERT()berechnen - Antworten zählen mit
=ZÄHLENWENN() - Diagramme erstellen: Balken-, Kreis- oder Säulendiagramme
- Das Datenanalyse-Add-In für t-Tests und Regression aktivieren
Mehr Details finden Sie in unserem Beitrag zu Statistik mit Excel.
Ja, SPSS eignet sich hervorragend für die Fragebogenauswertung — besonders im akademischen Umfeld. Typische Schritte:
- Daten importieren (CSV, Excel oder Unipark)
- Variablen in der Variablenansicht kodieren und Messniveau festlegen
- Cronbachs Alpha für Reliabilität berechnen
- Deskriptive Statistik durchführen
- Hypothesentests (t-Test, ANOVA, Chi-Quadrat) wählen
- Ergebnisse im APA-Format exportieren
Eine vollständige Anleitung finden Sie in unserem Artikel zur SPSS-Auswertung.
Eine Likert-Skala ist eine Bewertungsskala. Sie umfasst typischerweise 5 oder 7 Stufen. Diese reichen von „stimme überhaupt nicht zu" bis „stimme voll zu". In der Forschung dient sie der Messung von Einstellungen, Meinungen oder Zufriedenheit.
Auswertung in R:
- Mittelwerte und Standardabweichungen pro Item berechnen
- Reliabilitätsanalyse mit
psych::alpha()für Cronbachs Alpha - Kumulative Häufigkeitsdiagramme mit
stat_ecdf()aus ggplot2 - Divergierende Balkendiagramme mit dem
likert-Paket
Wichtig: Likert-Skalen sind streng genommen ordinal. Bei ausreichend vielen Stufen (5+) werden sie in der Praxis aber oft als quasi-metrisch behandelt.
- R / RStudio: Kostenlos, extrem leistungsfähig, reproduzierbar — ideal für komplexe Analysen und Publikationen
- SPSS: Benutzerfreundlich ohne Programmierkenntnisse — Standard in Sozialwissenschaften und Psychologie
- Excel: Für einfache Häufigkeitsanalysen und erste Übersichten geeignet
- JASP / Jamovi: Kostenlose Alternativen mit grafischer Oberfläche, ähnlich wie SPSS
Die Wahl hängt von der Komplexität des Projekts und den eigenen Vorkenntnissen ab. Für Abschlussarbeiten an Hochschulen die R oder SPSS verlangen, ist die jeweilige Software natürlich Pflicht.
Ja, Statistikerhub bietet professionelle Fragebogenauswertungen mit R, SPSS oder Excel. Typische Anwendungsfälle:
- Bachelorarbeit Fragebogen: Deskriptive Statistik, einfache Vergleiche, Visualisierungen
- Masterarbeit Fragebogen: Reliabilitätsanalyse, Faktorenanalyse, Regression
- Doktorarbeit: Strukturgleichungsmodelle, Mediator-/Moderator-Analysen
- Unternehmensstudien: Mitarbeiterbefragungen, Kundenzufriedenheit, Marktforschung
Wir übernehmen die komplette Auswertung — von der Datenaufbereitung bis zur Ergebnisinterpretation. Unverbindlich anfragen
Die benötigte Stichprobengröße hängt von mehreren Faktoren ab:
- Einfache Gruppenvergleiche (t-Test): Mindestens 30 Teilnehmer pro Gruppe
- Regressionsanalysen: Mindestens 10-15 Beobachtungen pro Prädiktor
- Faktorenanalysen: Mindestens 5-10 Teilnehmer pro Item
- Allgemeine Faustregel: Je mehr desto besser — ab 200 Teilnehmern sind die meisten Analysen stabil
Für die exakte Berechnung empfehlen wir eine Power-Analyse mit dem kostenlosen Tool G*Power.
- Mittelwerte für nominale Daten berechnen (z. B. Durchschnitt von Geschlecht)
- Keine Reliabilitätsprüfung der Skalen (Cronbachs Alpha vergessen)
- Zu kleine Stichproben für die gewählten statistischen Verfahren
- Fehlende Kontrollfragen — unaufmerksame Teilnehmer werden nicht erkannt
- Soziale Erwünschtheit nicht berücksichtigen bei sensiblen Themen
- Falsche Skalenniveaus anwenden (ordinale Daten als metrisch behandeln ohne Begründung)
- Fehlende Werte ignorieren statt systematisch behandeln (Imputation oder Ausschluss)
R selbst ist kein Umfrage-Tool — dafür eignen sich besser:
- SoSci Survey: Kostenlos für akademische Zwecke, sehr verbreitet im DACH-Raum
- Unipark / Questback: Professionell, oft über Universitäten lizenziert
- LimeSurvey: Open-Source, selbst gehostet, sehr flexibel
- Google Forms: Einfach und kostenlos, aber eingeschränkte Exportoptionen
Nach der Datenerhebung exportieren Sie die Ergebnisse als CSV und analysieren sie in R — das ist der empfohlene Workflow für reproduzierbare Forschung.